Using Dataflows and Power Automate for continuous data integration

Power Platform's Dataflows are a capable data integration tool that are often overlooked when it comes to transferring data out of Power Platform. They provide a wide range of connectors to extract and transform data from variety of sources. It is also possible to create custom connectors through a certification program. The typical target of a Power Platform dataflow is a table in Dataverse. But, there is also Analytical Dataflows.
Analytical Dataflows
Analytical dataflows transform data and store it in Azure Data Lake Storage accounts. This data can be used by other dataflows or Azure services, and can also be accessed from Power Automate's cloud flows. Accessing data stored by analytical dataflows is fully supported, and there are many valid use cases. One example is integrating dataflow data into internal applications and line-of-business solutions using developer resources for dataflows and Azure.
Bring your own data lake
If you haven't linked your environment to any Azure Data Lake Storage account, a default account will be used. This means you won't have direct access to that storage account. However, if you have linked your environment to an Azure Data Lake Storage account, when you start creating an Analytical Dataflow, you will be able to choose it as the target for your dataflow.
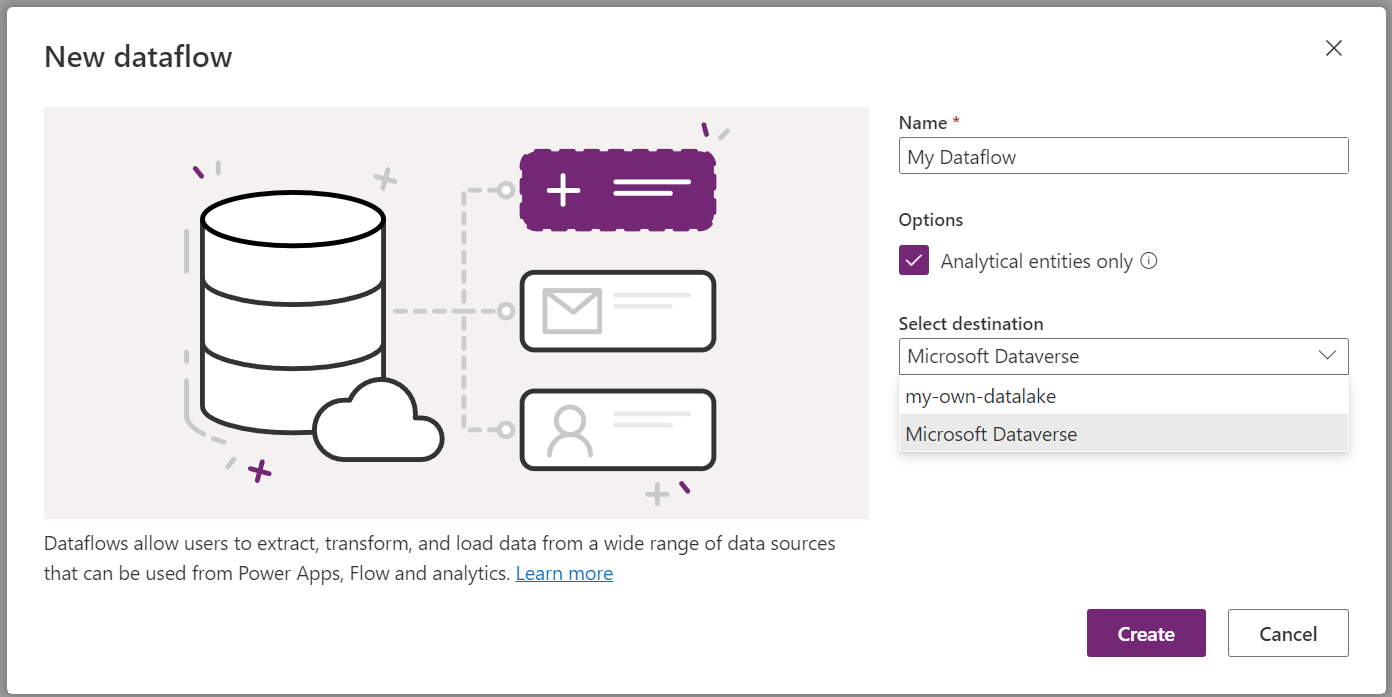
As you see in the following picture, when creating a new dataflow, if you select "Analytical entities only" checkbox, you will be given the option to choose your linked data lake as the destination of your dataflow.
After your dataflow runs, you will find the result in your data lake storage in a structure similar to the following.
power-platform-dataflows/└── environments/ └── your-environment/ └──your-dataflow/ ├── query1/ | └── query1.csv.snapshots/ | ├── beone_flow.csv@snapshot=14a9aa4b-d9... | └── ... ├── query2/ ├── query3/ ├── model.json.snapshots/ | ├── model.json@snapshot=14a9aa4b-d9... | └── ... └── model.jsonEvery time you update a dataflow, a new model.json file is made in the model.json.snapshots folder, and each query folder gets a new csv file. All these files from the same update will have the same unique identifier added to their names.
You can read more about Analytical Dataflows and their storage structure in Connect Azure Data Lake Storage Gen2 for dataflow storage - Power Query | Microsoft Learn but we are going to look into how we can use the data stored by dataflows from a cloud flow soon.
A common integration pattern
It won't be possible to provide a one-size-fits-all prescription for all kinds of outgoing data integrations, but let's imagine a common pattern that you can easily adopt to various requirements.
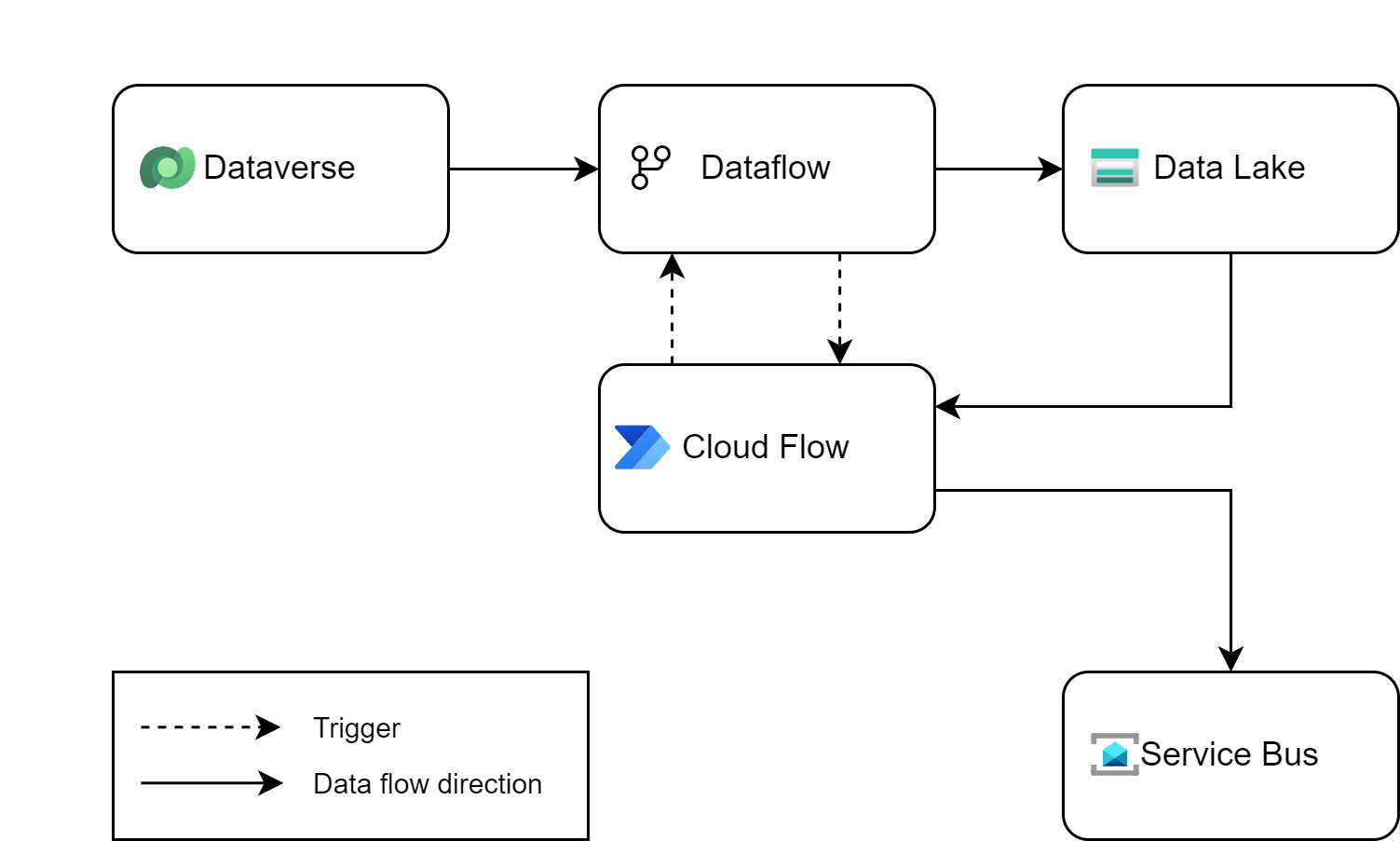
Dataflows excel in data extraction and transformation, while analytical data flows output results as CSV files. Power Automate, known for its automation capabilities, connects with a wide range of technologies. This allows for the strategic use of each tool based on its strengths: transforming data with Dataflows and then distributing it using Power Automate. There is a Dataflows connector in Power Platform, that contains a trigger and an action, simplifying the integration process.
- Refresh Completed - triggers a cloud flow when a dataflow completes its refresh.
- Refresh a Dataflow - Initiates refreshing a dataflow.
For our workflow, utilizing both the action and the trigger is essential. Here’s a concise overview of the process:
- Initiate the dataflow to extract and transform the required data, then export it to a data lake in CSV format.
- Upon dataflow completion, a cloud flow is triggered. This flow takes the CSV file, converts it to JSON (or XML), and then forwards it to Azure Service Bus or another specified destination.
For transferring substantial data volumes, it's advisable to segment your dataset into smaller portions and employ a parametric approach in your dataflow. This strategy transforms the process into a repeating cycle:
- Refresh the dataflow to extract and transform a segment of the data (for instance, by applying a filter on the 'createdon' column) and export it to a data lake in CSV format.
- Upon the completion of the dataflow, a triggered cloud flow takes the CSV file, converts it into JSON (or XML), and forwards it to Azure Service Bus or another chosen destination.
- The cloud flow then marks the processed rows as completed. If there are more rows to process, it initiates another cycle by starting a new dataflow. This process repeats until the entire dataset is transferred.
Things to consider
There are a few points that you need to be familiar with before starting to implement the solution.
Blobs as trigger - not an option
You might want to use "When a blob is added or modified" to start your cloud flow, but I advise against it. This is because dataflows could update the CSV files multiple times, not just once in your test. The frequency of file updates is an internal detail and can change anytime.
Limitations
Both low-code technologies we utilize in this pattern have limitations. The most notable limitation in Dataflow is the limitation of each dataflow to run only 48 times by a user. This limitation is not documented currently. I have in contact with Microsoft Support and as soon as I receive more clarification, I will update this blog post.
It is advisable to make your self familiar with the limitation of both technologies using the following official pages:
Dataflow Logs Table
You should know that, even though Dataflows can have parameters, there is no direct way to send parameters to a dataflow. Instead, you have to create a table to store your parameters. This table has other advantages, such as serving as a log to keep track of what has been sent and what is still remaining. To make this table reusable, you can consider using a structure like the following.
| Table Name | Dataflow Logs |
| Succeeded | Boolean |
| Name | Name of the dataflow that will use the log. |
| Parameters | String - can store the parameter values as JSON. |
Cloud Flow Logic
Below is a screenshot of a cloud flow that I have used in an integration project.
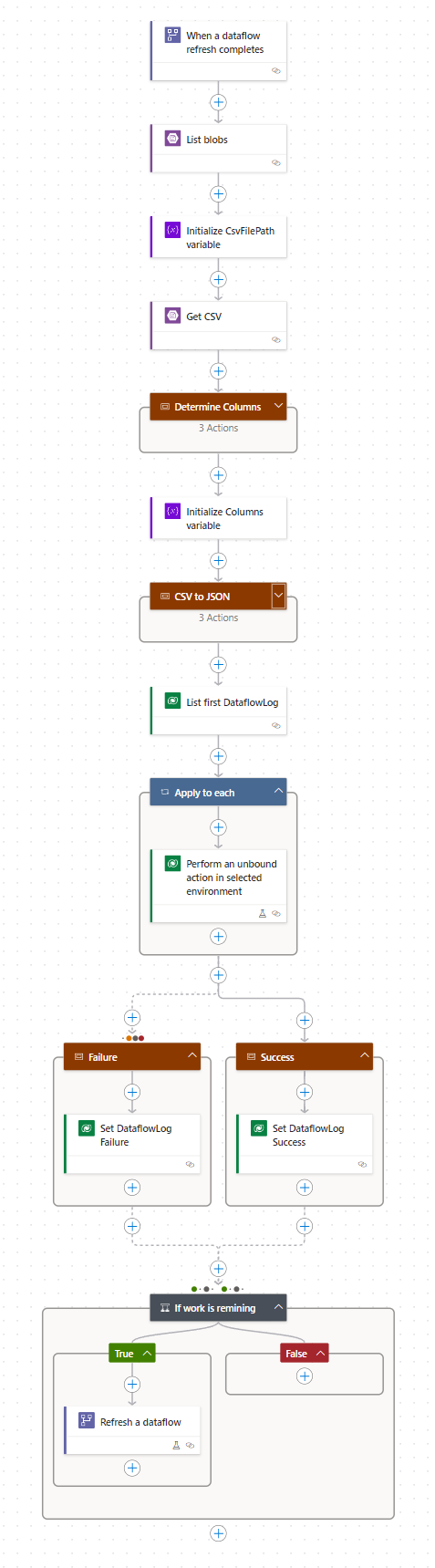
Let's walk through the cloud flow together.
- The trigger of the cloud flow is "When a dataflow refresh completed" and of course it points to the dataflow that does the data transformation for us.
- The first action is "List blobs" that lists the blobs in the specific folder within the data lake container that includes CSV files we need.
- The next steps just sort the list based on "LastModified" and picks the last one.
- The next few steps find the relevant data model file based on the name of the CSV file and determine the name of the columns. Remember, the CSV files have no header. So, we need to find he column names this way.
- Then the CSV file is then converted into JSON, using a Select action.
- Then an "Apply to each" loop will send the JSON objects to Azure Service Bus
- If the previous step is successful, we set the "Succeeded" column of the Dataflow Log table to True, otherwise we set it to False.
- Finally we check if there are any remaining rows in Dataflow Log table. If so, we use "Refresh a dataflow" action to start the dataflow again. This means the whole cycle will repeat until there is no Active rows remain in the Dataflow Log table.
Conclusion
Even though dataflows are better known for loading data into Power Platform, it is totally possible and supported to use them for autonomous outgoing data integration scenarios. To do this, you just need to add automation logic in Power Automate or another platform that can host the integration logic. Other alternatives could be Logic Apps, Azure Function Apps.