Data Migration as Code - Enhancing Observability and Reliability
In my previous post, I introduced the concept of Data Migration as Code in Power Platform, exploring how automation and scripting can bring consistency, repeatability, and efficiency to the migration process. I discussed the challenges of traditional data migration approaches, the benefits of treating migration as code, and how tools like PowerShell (using PSDataverse) and configuration-driven methodologies can streamline the process. If you haven't read it yet, I recommend checking it out before diving into this post.
At the end of my first post, we had this simplified script performing a basic data migration from a CSV file while measuring the time it took:
Import-Module PSDataverse
Connect-Dataverse https://test.crm4.dynamics.com
Measure-Object {
Import-Csv ./accounts.csv |
ForEach-Object {
@{
Uri = "accounts(my_migrationid=" + $_.accountid + ")"
Method = "PATCH"
Value = @{
name = $_.Name
address1_country = $_.Country
address1_city = $_.City
address1_line1 = $_.Line1
address1_line2 = $_.Line2
address1_postalcode = $_.PostCode
}
}
} |
Send-DataverseOperation -BatchCapacity 100 -MaxDop 10
} | Format-TimeSpanWhile this approach is functional for small datasets, it lacks observability, error handling, and scalability, making it unsuitable for large-scale data migrations. In this post, I’ll address these limitations and introduce a more robust architecture that ensures observability, reliability, and recoverability.
Observability
Although the above script might suffice for a small-scale import, real-world migrations often involve hundreds of thousands or even millions of records per dataflow. In such cases, we need mechanisms to monitor the process in real-time and answer key questions:
- How long will the data migration take?
- What is the success-to-failure ratio?
- What are the different types of failures?
- Which records failed and for what reason?
Key Observability Metrics
A truly observable migration should track:
- Total Records Processed
- Success vs. Failure Rate
- Error Classification (Validation, Connection, API Limit, etc.)
- Estimated Completion Time
Additionally, we must ensure error recovery so that failures can be analyzed, corrected, and retried without restarting the entire migration.
Transitioning from CSV to SQL for Scalability
The initial script used a CSV file as the data source. While this is simple, it does not scale for enterprise-level migrations. The main benefits of moving to a SQL-based approach or any data warehouse / bakehouse technology are:
- Scalability: These solutions can handle large datasets efficiently.
- Transactional Safety: Ensure atomicity and integrity.
- Advanced Querying: Enables powerful data transformation before migration.
- Better Performance: Reduces I/O bottlenecks compared to reading files.
Let’s modify the migration process to use SQL Server instead of a CSV file and use variables to store reusable values.
Import-Module PSDataverse
$SourceConnectionString = "Server=MySQLServer;Database=MigrationDB;Integrated Security=True;"
$DestinationConnectionString = "https://test.crm4.dynamics.com"
$ExtractQuery = "SELECT CompanyId, Name, Country, City, Line1, Line2, PostCode FROM Companies"
Connect-Dataverse $SourceConnectionString
Measure-Object {
Invoke-DbaQuery -SqlInstance $DestinationConnectionString -Query $ExtractQuery |
ForEach-Object {
@{
Uri = "accounts(my_migrationid=" + $_.CompanyId + ")"
Method = "PATCH"
Value = @{
name = $_.Name
address1_country = $_.Country
address1_city = $_.City
address1_line1 = $_.Line1
address1_line2 = $_.Line2
address1_postalcode = $_.PostCode
}
}
} |
Send-DataverseOperation -BatchCapacity 100 -MaxDop 10
} | Format-TimeSpanReliability
Clients often expect 100% accuracy in data migrations. To achieve this, we must:
- Store proof of every successful operation.
- Capture failure reasons to allow corrections and retries.
- Handle intermittent failures (e.g., API timeouts, brief disconnections, rate-limiting / throttling).
The good news is PSDataverse can automatically handle intermittent failures using internal retry and circuit breaker policies, so we can focus on the first two issues.
In cases that Power Platform refuses an operation due to validation failures of other unrecoverable errors, it will send back an error object as response that looks like the following example.
{"code":"0x80040217","message":"Account With Id = 92d55f0d-bd4a-e211-a01d-00505681003a Does Not Exist"}Architecture
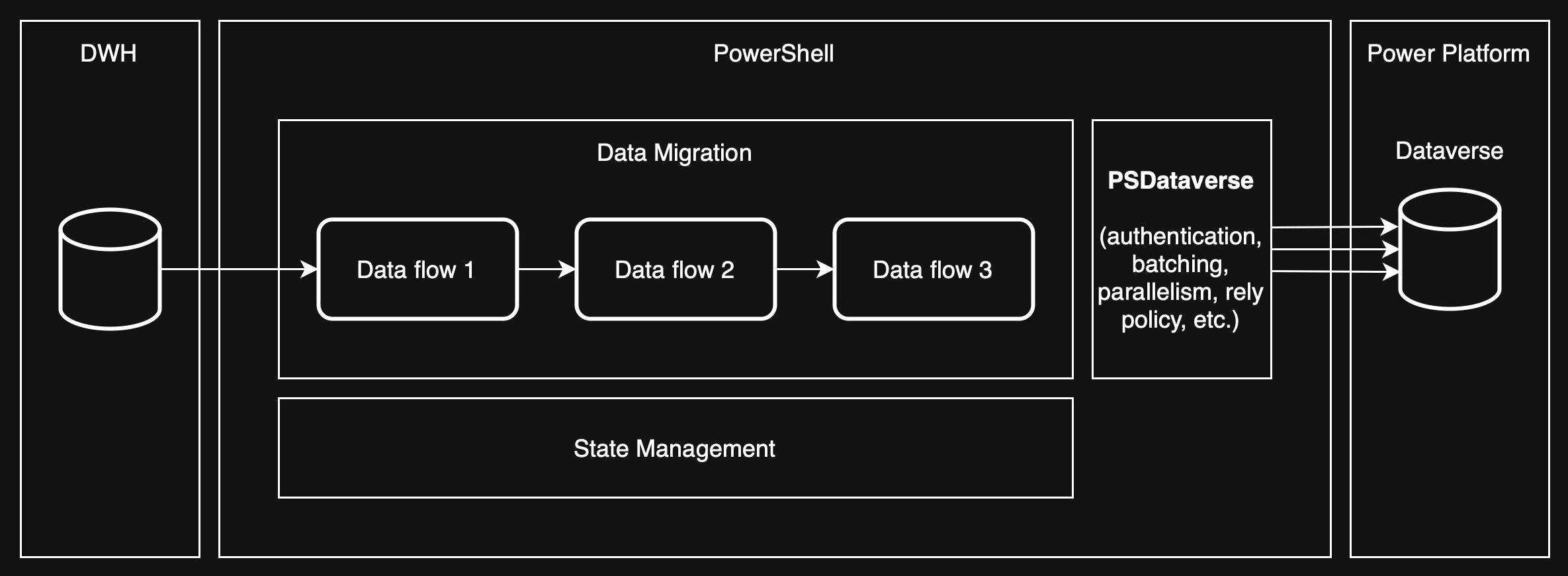
We need a simple architecture that can be easily adapted for any data source, provide observability and maintain the state of data migration. The underlying technologies we choose should also provide the level of reliability that we expect. This is one of the reasons I switched to SQL Server, but it can be any DWH, or even a Lakehouse. Depending on what is accessible and allows you to iterate faster. One of the advantages of PowerShell and a simple DWH like SQL Server or PostgreSQL is that their setup takes minutes and they are accessible in any environment making the ideal in data migration from on-premise to cloud. Let's see our setup looks like in simple diagram.
OperationHistory table
To persist both success and error responses we need a history table. This table will enable us to monitor, analyze, troubleshoot and even retry operations. I propose a simple structure to minimize storage and complexity.
| Column | Description |
|---|---|
| Id | The primary key depending with the same type as the source of data migration e.g. uniqueidentifier |
| BatchId | When we use BatchCapacity higher than 1, multiple operations will be sent in a batch. This column will help us distinguish which operation was sent in which batch. |
| Response | The response of the operation sent to the API. |
| CreatedOn | A datetime field that indicates when the response was receieved / stored. |
| ModifiedOn | Another datetime field that indicate when the response was updated. This column will have different value than CreatedOn when we retry an operation. |
Logging Strategy
A proper logging mechanism is crucial for debugging and auditing migrations. Here’s a basic PowerShell logging function:
function Write-Log {
param (
[Parameter(Mandatory)][string]$Message,
[Parameter()][ValidateSet("Info", "Warning", "Error", "Debug")] [string]$Level = "Info",
[Parameter()][string]$LogFile = "$PSScriptRoot\log.txt",
[Parameter()][switch]$NoFileLog
)
$timestamp = Get-Date -Format "yyyy-MM-dd HH:mm:ss"
$logEntry = "[$timestamp] [$Level] $Message"
switch ($Level) {
"Info" { Write-Verbose $logEntry }
"Warning" { Write-Warning $Message }
"Error" { Write-Error $Message }
"Debug" { Write-Debug $Message }
}
if (-not $NoFileLog) { Add-Content -Path $LogFile -Value $logEntry }
}Save-OperationHistory implementation
We need a function to store the responses coming back from the API. The implementation of this function depends on the data storage we chose before. In case of SQL Server, the function needs to store the responses in the OperationHistory table, something as simple as the following example:
function Save-OperationHistory {
param (
[Parameter(Mandatory, ValueFromPipeline)]$Result,
[Parameter(Mandatory)][string]$ConnectionString
)
process {
try {
if (-not $Result) {
Write-Log "No operation data to store." -Level Debug
return
}
Invoke-DbaQuery -SqlInstance $ConnectionString -Query "[Migration].UpsertBatchOperationHistory" -SqlParameters @{
BatchOperationHistory = $Result
} -CommandType StoredProcedure
}
catch {
Write-Log "Store-OperationHistory encountered an error: $_" -Level Error
}
}
}In the above function, I'm just getting the responses from the pipeline and sending them to a simple stored procedure to store them in the OperationHistory table. In real-world scenarios, however we need to do more than that. For example you can have data flows that send only a few hundred operations or even less, so you might prefer to send the operations one-by-one, hence responses will come back one at a time and you would store them one-by-one as well. In larger data flows you might need to batch hundreds of operations as batches, hence receiving response as batches too. Storing batch responses one operation at a time can introduce latency in your data flows.
Improving performance
In case of SQL Server, depending on the size of dataset, different approaches will be optimal. For example for a few dozen rows, it would be faster to send them as a table parameter, but for larger number of rows it can be faster to bulk load them to a table and merge them to the OperatioHistory table in a second step. The responses can also vary depending on the success, failure or parameters we use for Send-DataverseOperation command. For example by adding -OutTable, batch responses will come back as DataTables. A better version of Save-OperationHistory would look like the following.
function Save-OperationHistory {
param (
[Parameter(Mandatory, ValueFromPipeline)]$Result,
[Parameter(Mandatory)][string]$ConnectionString
)
process {
try {
if (-not $Result) {
Write-Log "No operation data to store." -Level Debug
return
}
$operationType = $Result.GetType().Name
Write-Log "Processing operation of type: $operationType" -Level Info
if ($Result -is [System.Data.DataTable]) {
Write-Log "Using provided DataTable" -Level Debug
$tbl = $Result
} else {
$tbl = New-Object System.Data.DataTable
$tbl.Columns.Add("Id", [Guid]) | Out-Null
$tbl.Columns.Add("BatchId", [Guid]) | Out-Null
$tbl.Columns.Add("Response", [string]) | Out-Null
$tbl.Columns.Add("Succeeded", [bool]) | Out-Null
}
if ($Result -isnot [System.Data.DataTable]) {
foreach($Operation in @($Result)) {
if ($Operation -is [PSDataverse.Dataverse.Model.OperationResponse]) {
Write-Log "Handling single successful operation" -Level Info
$tbl.Rows.Add($Operation.ContentId, [Guid]::Empty, $Operation.Headers["OData-EntityId"], 1)
} elseif ($Operation -is [PSDataverse.Dataverse.Model.BatchResponse]) {
Write-Log "Handling batch successful response" -Level Info
foreach ($op in $Operation.Operations) {
$tbl.Rows.Add($op.ContentId, [Guid]::Empty, $op.Headers["OData-EntityId"], 1)
}
} elseif ($Operation.Exception) {
$errorType = $Operation.Exception.GetType().Name
if ("OperationException`1" -eq $errorType) {
Write-Log "Handling single operation failure" -Level Info
$tbl.Rows.Add($Operation.Exception.Operation.ContentId, [Guid]::Empty, $Operation.Exception.Error.ToString(), 0)
} elseif ("BatchException`1" -eq $errorType) {
Write-Log "Handling batch failure" -Level Info
foreach ($op in $Operation.Exception.Batch.ChangeSet.Operations) {
$description = if ($Operation.Exception.InnerException -and
$Operation.Exception.InnerException -is [PSDataverse.Dataverse.Model.OperationException] -and
$op.ContentId -eq $Operation.Exception.InnerException.Operation.ContentId) {
$Operation.Exception.ToString()
} else {
"Batch failed due to: $($Operation.Exception)"
}
$tbl.Rows.Add($op.ContentId, $Operation.Exception.Batch.Id, $description, 0)
}
} else {
Write-Log "Unsupported exception type: $errorType" -Level Warning
Write-Log "Full error details: $($Operation.Exception)" -Level Error
}
} else {
Write-Log "Unsupported response type: $operationType" -Level Warning
}
}
}
if ($tbl.Rows.Count -le 50) {
Write-Log "Using Invoke-DbaQuery for small batch" -Level Debug
Invoke-DbaQuery -SqlInstance $ConnectionString -Query "[dbo].UpsertBatchOperationHistory" -SqlParameters @{
BatchOperationHistory = $tbl
} -CommandType StoredProcedure
} else {
Write-Log "Using SqlBulkCopy for large batch ($($tbl.Rows.Count) rows)" -Level Info
BulkInsert-OperationHistory -ConnectionString $ConnectionString -DataTable $tbl #-Environment $Environment
}
}
catch {
Write-Log "Store-OperationHistory encountered an error: $_" -Level Error
}
}
}We can divide Save-OperationHistory in two halves. The first half checks if the result is already a DataTable. If not, it will create a DataTable and fill it with the right information depending on the type of result. For example for a single successful operation result, it will extract OData-EntityId header which contains the full URL of the created / updated record. The second half, decides depending on the number of the rows in the DataTable, how to store them in OperationHistory table. For smaller number of rows, it will simply send the DataTable as a parameter to a stored procedure to take care of storing them, but for larger number of rows, it will use the bulk load technique.
Stay tuned for my next blog post where we iterate over our data migration script to:
- Allow multi-dataflow scenarios.
- Incorporate some of the best practices expected and make it more robust.